CRLiteの仕組み:Bloom filterの偽陽性をなくす方法
はじめに
TLS証明書の失効情報を管理する新たな仕組みとして、CRLiteというものが考えられています。(以下の論文です)
CRLiteの根幹部分は、偽陽性を排したBloom filterで成り立っています。
この記事では、どのようにしてそのような偽陽性のないBloom filterを作るのか記載します。
まずは、Bloom Filterについて説明します。
Bloom filterについて
概要
Bloom filter(以下、BF)自体は1970年に考案されたデータ構造なだけあり、既に様々なウェブサイトにて解説がなされています。 このデータ構造の典型的な使い道の一つとして、ブラックリストがあります。あるデータが、許容されないリスト(ブラックリスト)に記載されているか否かを判別したいとき、これを用いることで高速に(どんなにブラックリストが大きくなっても定数時間で)判別を行うことができます。
但し、素のBFにはデメリットとして偽陽性(False Positive)があります。
偽陽性:本当はリストに含まれて いない データなのに、含まれて いる と判別してしまう。
なお、偽陰性はありません。
偽陰性:本当はリストに含まれて いる データなの、含まれて いない と判別してしまう。
言い換えると、「含まれている!」という判定をBFから得た時は、誤りである可能性があります*1が、「含まれていない!」という判定を得た時は、確実に正しいということです。
仕組み
適当なサイズの配列と、適当な個数のハッシュ関数*2を用意することでBFを構築することができます。たとえば、配列長8、ハッシュ関数2個(md4とmd5とします)の場合を考えます。
データの追加
appleという文字列を追加することにします。追加するデータに対して、先のハッシュ関数でハッシュ値を求めます。ハッシュ値(整数)は、配列のインデックスの為に使用します。ただ、ハッシュ値そのままでは長大ですから、配列長に収まる数となるように配列の長さで割った余りを求めます。
| データ | ハッシュアルゴリズム | hash値 | hash値を8で割った余り(インデックス) |
|---|---|---|---|
| apple | md4 | 0x9443a56f029a293d8feff3c68d14b372 | 2 |
| apple | md5 | 0x1f3870be274f6c49b3e31a0c6728957f | 7 |
求めたインデックスが指し示す配列の値を、1にしておきます。BFではこれでデータを追加したこととなります。
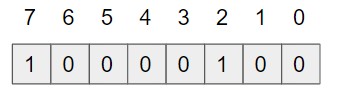
データの存在確認
先のBFに、データorangeが存在しているか確認してみます。まず、同様にハッシュ値を求めます。
| データ | ハッシュアルゴリズム | hash値 | hash値を8で割った余り |
|---|---|---|---|
| orange | md4 | 0xb0e795cd4b8b3c8247a09cbcd6f4a76c | 4 |
| orange | md5 | 0xfe01d67a002dfa0f3ac084298142eccd | 5 |
求めたインデックスを用いて配列の値を確認し、全てが1である場合はデータが存在するということとなります。
そうでない場合、1つでも0の箇所があるなら、データorangeは存在しないこととなります。
今回の場合、配列[4]と配列[5]の値はどちらも0なので、orangeは存在しないこととなります。
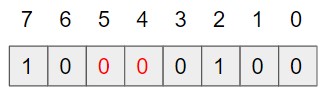
性質
先の例のように、データを追加する時も検索するときも、必要なのは固定回数のハッシュ値の計算と配列参照だけです。そのため、どんなにデータが増えても処理時間に問題が生じることはありません。また、データの追加に伴って配列が長くなることもありません。これは、BFのメリットです。
一方で、orange以外のデータで偶然配列の番号が4,5となるようなものがあったとします。そうすると、誤ってBFにデータが含まれていると判断する原因になります。これは、データが追加され配列の中が埋まっていくほど発生しやすくなります。これは、BFのデメリットです。
改善
なお、配列長や用意するハッシュ関数の個数を調整することで、BFの偽陽性を減らすことはできます。ただし0にすることはできません。
BFで管理したいデータの見込み数や、偽陽性の確率を入力すると適切な配列長やハッシュ関数の数を計算してくれるサイトがありますので、こちらを参考にすると良さそうです。
Filter Cascade Design
BFの偽陽性なくす方法について説明します。
残念ながらいつでも偽陽性をなくすことができる、というわけではありません。
BFを作成する時点で、BFに追加するデータと 追加しないデータ の全て(これを、 $ U $ とします)が分かっている場合、BFを多段に構築(カスケード)することで偽陽性をなくすことができます。
ここでは追加するデータの集合を $A$ とし、追加しないデータの集合を $B$ とします。 $ A \cup B = U, A \cap B = \varnothing $ であるとして、構築手順の例を説明します。
データの追加
- $ A $を用いて通常通り、素のBFを構築します。これを、$ BF_1 $ とします。
- $ BF_1 $ が判断を誤ってしまうデータを見つけ(そのようなデータは、 $B$の要素として存在することとなります)、これを $ FP_1 $ とします。
- もし、$ FP_1 = \varnothing $ であるなら、偽陽性のないBFの完成です(1段)。そうでないなら、次の手順を続けます。
- $ FP_1 $を用いてBFを構築します。これを、$ BF_2 $ とします。
- $ BF_2 $ が判断を誤ってしまうデータを見つけ(そのようなデータは、 $A$の要素として存在することとなります)、これを $ FP_2 $ とします。
- もし、$ FP_2 = \varnothing $ であるなら、偽陽性のないBFの完成です(2段)。そうでないなら、次の手順を続けます。
- $ FP_2 $を用いてBFを構築します。これを、$ BF_3 $ とします。
- $ BF_3 $ が判断を誤ってしまうデータを見つけ(そのようなデータは、 $FP_1$の要素として存在することとなります)、これを $ FP_3 $ とします。
- もし、$ FP_3 = \varnothing $ であるなら、偽陽性のないBFの完成です(3段)。そうでないなら、次の手順を続けます。 (以下、省略)
このようにして、多段のBFを作成します。この例では、$ FP_3 = \varnothing $であったとして3段のBFを作成したものとします。
データの存在確認
上記で作成した多段のBFに順々に問い合わせを行うことで、確認します。